
The OpenMP Explorer
| Home | |
 |
Back To Tips Page |
|
The OpenMP Explorer |
|
Some time ago, I had to create a talk about the OpenMPsupport. OpenMP is an industry-wide standard which allows an OpenMP-compliant compiler to use the #pragma declarations (if in C/C++) to interface to the OpenMPruntime.
This is not a tutorial on OpenMP. This is an illustration of the use of some of the OpenMP features.
This is the OpenMP Explorer window
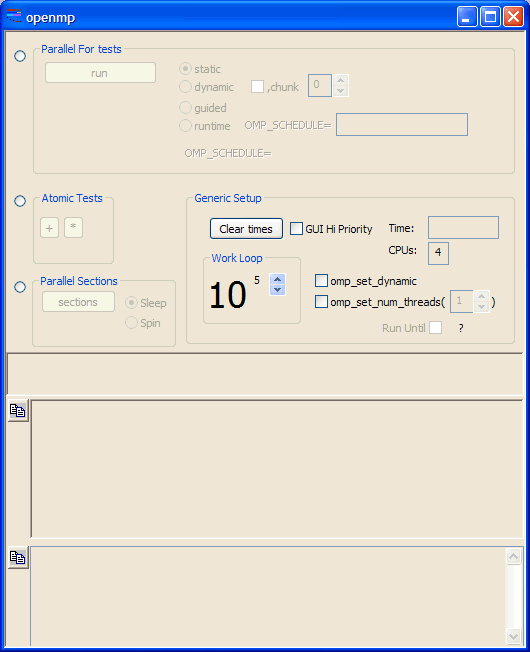
There are three sets of tests, but only the first and third are currently interesting. The "Atomic Tests" was created to allow you to set a breakpoint in the source and single-step the code to see how the code actually works.
The above screen capture is from a dual-processor, hyperthreaded, Pentium-class machine, which appears as a 4-processor system.
If "Parallel For" is selected, the options available are static, dynamic, guided and runtime. These correspond to the OpenMP options, which appear in the code window.
The copy button, ![]() , will copy its
corresponding window to the clipboard.
, will copy its
corresponding window to the clipboard.
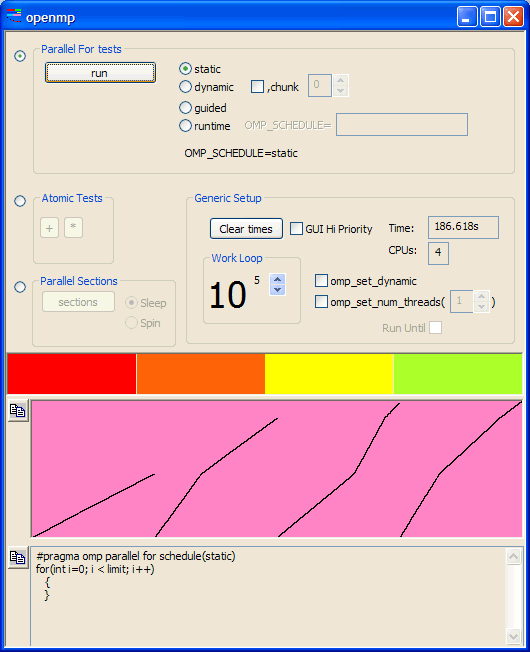
This shows that there were four parallel-for threads. In the graph, the vertical axis is total computing time, slightly over three minutes. Note that the threads are not quite parallel and do not finish in order, because there are many other programs running on the machine.
| Style | Parameters | Time | Graph |
|
dynamic |
default chunk size |
189 sec |
 |
| dynamic | chunk=8 | 193 sec |  |
| guided | 189 sec |  |
Note there is no significant performance difference using the three methods, under the Microsoft VS2005 compiler and XP Pro SP2 on 32-bit Pentium-class hyperthreaded dual-processor machines. Your Mileage May Vary.
The Parallel Sections test shows how OpenMP can break computations into parallel threads without any particular user intervention in terms of threading; just adding the declarations will accomplish the task.
Note also there is no sharing of data between the threads.
The default configuration does the first computation; the number of threads is the default, which is the number of CPUs.
The lower level of dots is showing the main thread. The upper threads show the computation for each of the eight sections, which computes in 9 seconds. The second graph shows what happens if we set the number of threads to 1; the computation takes 22 seconds (the x-axis for the graph is the number of threads, which are 1 for the current experiment and 4 for the first experiment, so it is plotting time on the y-axis vs. number of threads on the x-axis. Note that up to 8 threads, we get a performance improvement, even on a 4-CPU system, but the improvements get smaller and smaller as we add threads.
| Threads | Time | Graph |
|
default (4) |
9 sec |
 |
| 1 | 22 sec |  |
| 2 | 13.25 sec | 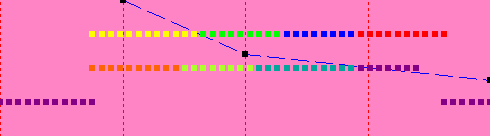 |
| 3 | 11 sec | 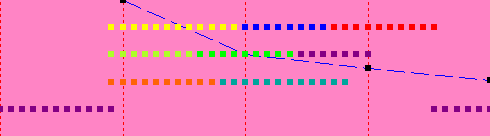 |
| 4 | 9 sec | 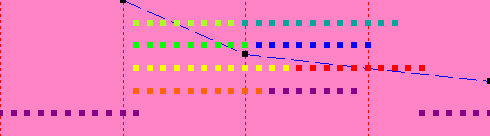 |
| 5 | 8.5 sec | 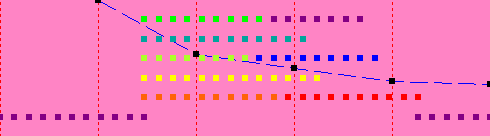 |
| 6 | 8 sec | 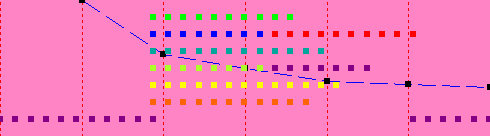 |
| 7 | 7.5 sec | 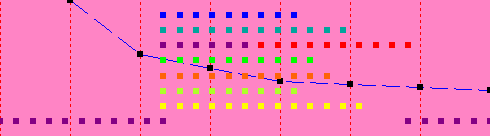 |
| 8 | 6.75 sec | 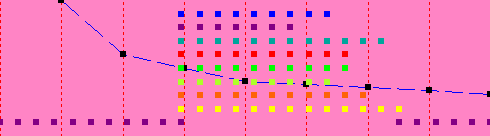 |
| 1..8 |  |
In the last test, the Run Until checkbox was set, and the complete set of tests, from 1 thread to 8 threads, were run and the results are displayed in a single graph.
This is only a subset of the OpenMP capabilities; perhaps someday I will enhance it.

![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.