
Inside A Storage Allocator
|
|
Home |
 |
Back To Tips Page |
|
|
Inside A Storage Allocator |
|
I find it quite amazing that almost no one seems to understand how a storage allocator works. People have buffer overruns and don't understand what happened. They get assertions from within the allocator and their brains freeze. They ask questions like "If I fail to free all my memory before I exit my program, will the system lose memory?", which shows a complete lack of understanding of how any part of the operating system works.
Why is this? Apparently because courses teach only Java or C#, in which allocation is not an issue (it all happens By Magic), and teach nothing about how programs run in operating systems, or how malloc or new actually work internally. In many years of teaching advanced programming courses at either the application level or the kernel level, I have found very, very few students, including those who have been programming for a number of years, who have any clue whatsoever about how storage allocation actually works internally.
I have written storage allocators for DECSystem-10, DECSystem-20, IBM 360/67, PDP-11, the x86 family, the Z-80, the 680x0 family, and probably a few machines I've forgotten; in many cases, I have written more than one allocator for a platform, sometimes writing an allocator unique to a single application. I've written allocators in a variety of languages on each platform. If all the blocks are fixed size, I can write an allocator in about ten minutes. I never thought storage allocators were a particularly difficult concept. But apparently no college course takes the time to teach about allocators, or even give an assignment to do so (my first real allocator was written in FORTRAN as a student exercise in list processing, in 1967, so I've been writing allocators for 42 years as of 2009).
When I teach my System Programming course, students are required to write a little storage allocator that allocates blocks of fixed size in shared memory. What surprises me, every single time, is that the students have never, ever seen how an allocator works; it got to the point where I actually have to put the code in my slides so they can copy it (well, almost. They have to understand it because a straight copy will not work for the assignment!). In our Device Driver course, it is not uncommon for students to accidentally overwrite kernel memory, and get a "Bad Pool Header" bluescreen. They have no idea what this message might mean, or how it might be caused. For all practical purposes, there is zero understanding out there about one of the most fundamental features of our runtime environment.
This essay is intended to explain how allocation works. It includes a real, genuine, actual, bona fide storage allocator example, with the code explained. It includes a program that actually shows an animation of the allocator running and shows the state of memory.
I have two other essays on storage allocation, About Memory Allocators (which overlaps a lot with this essay, but discusses other topics I don't cover here), and one on how to deal with analyzing storage damage bugs, An introduction to memory damage problems. I had hoped that these would have been sufficient, but that has turned out to not be the case.
This allocator operates in about 130 lines of code (counting the separate lines of open brace and close brace), and strictly speaking, for actual executable lines of code (not counting function headers and lines that are just open brace or close brace) there are fewer than 100 lines that actually do computation. Therefore, as an example of the basic principles of storage allocation, it is about as simple as I could make it. It is not fully general, it does not guarantee portability to other platforms, it is not as efficient as an allocator could be, it is not as robust as an allocator could be, it does not provide any aid for debugging, it fragments memory badly, and in general there is a lot that real allocators do that this one does not. But nothing that a real allocator does in any way is philosophically different than the code you see here. All changes in real allocators are simply to improve performance and reliability.
The term used to describe the allocatable space in a project has, historically, had many different names. Most commonly it is referred to as "the heap", because it is just a pile of bits, distinguished from "the stack" or "static variables". But it has also been referred to as "the free storage", "the storage pool", "the pool" (the name the Kernel uses for its heaps), and several other lesser-used terms. They all refer to a concept of storage from which objects can be allocated. Operations such as new (in C++ or C#) or malloc/calloc (in C) will allocate space from this storage. The storage is returned by some mechanism. In C, the free operation fulfills this role. In C++, it is delete. In languages like Java and C#, there is no explicit operation to free storage; instead, the system automatically detects storage that is not being used and returns it to the collection of available space.
When a process is created, a process control block is created in the kernel, and virtual memory is allocated to the process. This memory is then loaded with the code and data for the program, and the program starts execution. One of the things that happens is that the default heap is created. All malloc operations obtain their space from the default heap. The default implementation of new in C++ is in terms of malloc.
At this point there is one, and precisely one, way to add new memory to the process's virtual address space: VirtualAlloc (we will ignore VirtualAllocEx and VirtualAllocExNuma, since they are just VirtualAlloc with a few trivial features added). None of the common APIs such as malloc, new, HeapCreate, or HeapAlloc can allocate memory to the process; when they need memory, they call VirtualAlloc. Whether they do it directly from user-level code or internally in the kernel code doesn't make any difference.
Virtual memory is an imaginary concept. We lie to the process and tell it that it has, for example, a contiguous buffer a megabyte in length. In fact, the only guarantee is that there is a contiguous range of virtual addresses. They may or may not occupy actual physical memory on the machine. Because there can be more virtual memory required than there is physical memory on the machine, some of the pages of VM are written to the disk. If they are needed, they are loaded.
The mapping between virtual addresses and physical addresses is managed by the CPU hardware. When an instruction that touches memory executes, the address is presented to the virtual memory hardware component of the CPU. The address is looked up in a table, the page table, and the actual physical address is placed on the memory bus. Therefore, the pages of your buffer are almost certainly not physically contiguous in memory, and in fact may not even be in memory. If a page is not present, a bit in the entry in the page table says "this is on the disk" and the remaining bits of the "physical address" can be used to indicate where on the disk the actual page may be found (for example, a disk sector address).
Note this is a simplified explanation; in real systems, such as the Intel x86 processor and the Windows operating system, the management of all this paging is handled by hardware a good deal more sophisticated than this simple example will suggest, in order to save time and space required to do the page lookup. A special cache on the machine, called the Translation Lookaside Buffer (or TLB) keeps track of recent page translations so it is not necessary to keep going back to the map, which is stored in ordinary memory.
Note that devices that are doing I/O by using Direct Memory Access, where the device grabs the processor bus and sends data directly to memory, completely bypass the page mapping. Therefore, they have to be programmed in terms of the physical address of the page in memory. This discussion takes several hours in a course on device drivers and is not appropriate here, but be aware that there are parts of the operating system that really, really care where those pages actually are, even if briefly (such as for the duration of a single I/O operations).
When an instruction presents an address that is marked as "not present in memory", an access fault is taken. The operating system looks at the nature of the fault, determines that it occurred because the page had been moved out to the disk, and therefore finds an unused page in memory, reads the page stored on the disk into that space in memory, modifies the page table to show where the page now resides, and then adjusts the instruction pointer (EIP/RIP) to point to the instruction that failed and resumes execution. The memory access will now succeed.
Of course, this assumes that there is a hole in memory where the page can be read in. If there isn't, one must be created. If there is a page in memory that has been already written to the disk, and that page has not been modified, it can be used for this purpose. It is first necessary to locate which page table(s) refer to it, and replace their references to this page to indicate that the page is no longer present. Then the page you need can be read into that space and your page table entry updated to refer to that page in memory.
But if there is no "clean" page in memory, some existing page must be first written to disk. Once it has been successfully written to disk, the procedure described in the previous paragraph, to reuse an existing page, can be applied.
One of the questions that all too often comes up is "I need 4GB to hold all my data. So I put 4GB of memory on my machine, and I'm still running out of memory, somewhere around 2GB. What's wrong?"
What's wrote here are two failed understandings. First, the amount of physical memory does not change the amount of space available to a process. A process is allowed to use 2GB of address space (minus 64K on each end) to hold data. There is no way in Win32 that a process will be able to have 4GB of space. It can't even have 2GB of space for data, because some of that space is used to hold your code, your static data, all the code and data for all the DLLs that you need (including the substantial Win32 API DLLs), and so on. You can, on Win32, cause it to boot with a 3GB user address space capability, but then you need to make sure your program is linked with the /LARGEADDRESSAWARE option to the linker or the operating system will refuse to allow it to have more than 2GB.
But because of virtual memory, you can run a 2GB (or even 3GB) process on a 512MB machine. All that happens is that there is a lot more paging. More memory does not create more address space, only better performance.
To prevent any one process from "hogging" the entire machine, a process's use of memory is limited by requiring that it live within a working set of a limited number of pages. If the process consumes more pages than it is permitted to use, then its extra pages will be forced out to disk.
You can run out of memory before hitting even the nominal 2GB limit. All those pages have to go somewhere, and that somewhere is the paging file, pagefile.sys. You can have paging files on several of your hard drives (which can improve performance) but if you run out of disk space to write pages out, no more pages can be created. If you have ten processes each requiring 2GB, then you will need 20GB of paging file. If you can't get it (either because there is not available space on the disk, or the administrative limits imposed on your account restrict the total paging space you can consume) then the operating system will refuse to honor a VirtuallAlloc request.
When a process terminates, all the virtual memory allocated to the process is freed. Period. It all goes away. The kernel does not care if the contents of that memory are code, data, a heap block marked as "allocated" or a heap block marked as "free", it all goes away. Therefore, it is impossible for a terminated process to consume memory because "it had a storage leak". A storage leak is a concept that has no relevance to the kernel's view of your program; it is a concept that exists solely within the address space. When the address space goes away, the memory is freed to the kernel. There is simply no concept of "leaking kernel memory" because you have a "storage leak" in your code.
One of the classic questions, "If my program terminates abnormally and I haven't freed all the memory, will I leak kernel memory?" is therefore trivially answerable. When your process terminates, all the memory is freed. Nobody cares at that point whether the memory is static data, code, or heap; it all goes away, always, no exceptions. It is gone.
Because if you get a listing of the storage leaks, it usually indicates a bug in the program. If you fail to free memory you are no longer using, even though you know that it doesn't matter, you can't tell this legitimate failure to free memory from actual bugs that really are leaking memory. So if you are careful, and free everything, then any storage leaks that are reported are truly leaks, and represent errors in your code.
This little example is just about the World's Second Simplest Storage Allocator (the World's Simplest Storage Allocator is discussed later).
Actually, it is the Third Simplest Storage Allocator, because this allocator actually is thread-safe. The Second Simplest Storage Allocator does not care about threads and would malfunction horribly in a multithreaded environment.
 How does the allocator work?
How does the allocator work?A typical storage allocator takes the block of memory provided and places some kind of control header at the front of it. I will refer to this block as a heap segment. In my simple allocator, the heap segment header contains only two pieces of information, the size of the heap segment, and a CRITICAL_SECTION to provide the thread-safe lock. It then divides the remaining memory into two classes of storage, allocated storage, which is "owned" by some component of the calling program, and free storage, which is owned by the allocator. The allocator is not permitted to do anything to allocated memory, except free it when the programmer asks to free it. It is free to do whatever it feels like with the free storage. The heap segment contents will be divided into memory blocks. Each memory block will have a header at the front, which is not part of the visible space a user of the allocator sees, and there is always at least one such memory block.
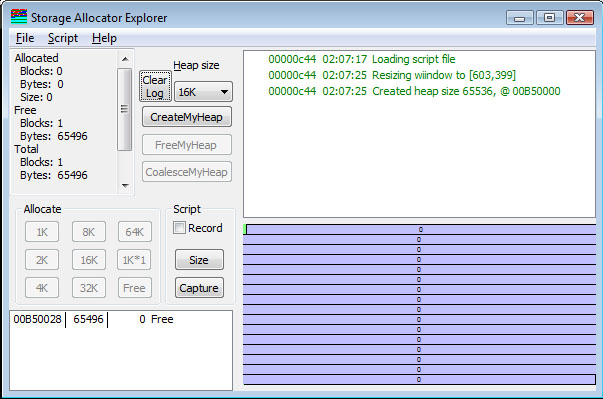
When the allocator starts, all the storage is free, so there is a single heap segment header for the entire heap segment, and a single block header saying all the rest is free. This is shown below.
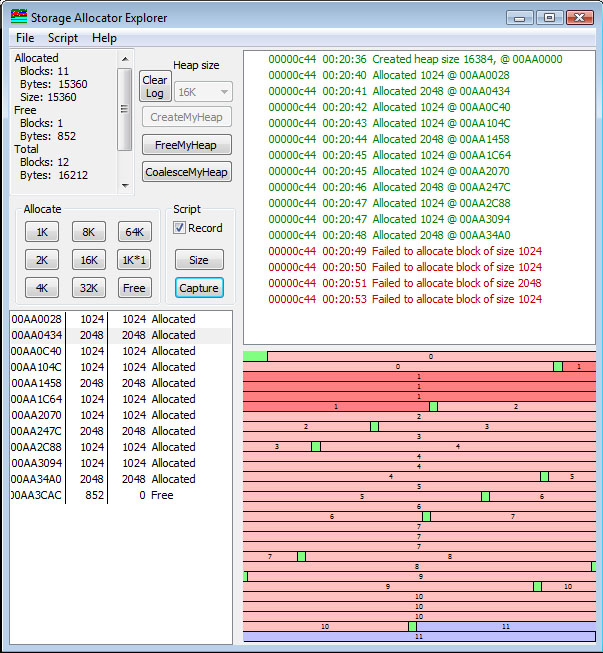
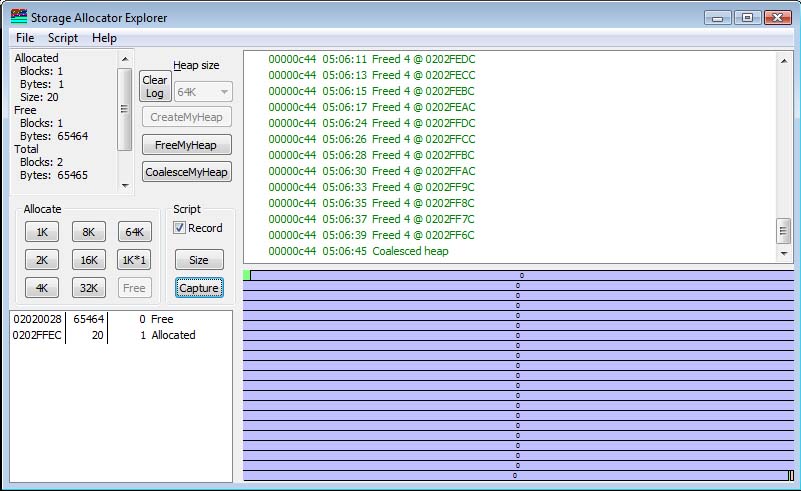
Notice the text in the left box. It shows the total number of allocated blocks and the total number of free blocks, as well as the number of bytes accounted for in the allocated and free blocks. Note that the sum of bytes, split between the allocated space and free space, does not total the number of bytes in the heap segment. This is because there is some overhead. Note the slight offset of the start of the block from the left edge. This is the space occupied by the heap segment header and the block header for the one-and-only current block in the storage pool.
The columns of the ListBox in the lower left corner give the address of the block (the application-visible address), the size of the block, and the number of bytes of the block that were requested. If the number of bytes allocated is 0, then the block is free. However, allocations are always "rounded up" to some integral boundary (in my little allocator, to a 4-byte boundary), so a block whose size is 1 would appear to use 4 bytes. A block of size 5 uses 8 bytes, and so on. Note that the sizes shown in the memory layout are are the sizes of the actual allocated space, either 4 or 8 bytes.
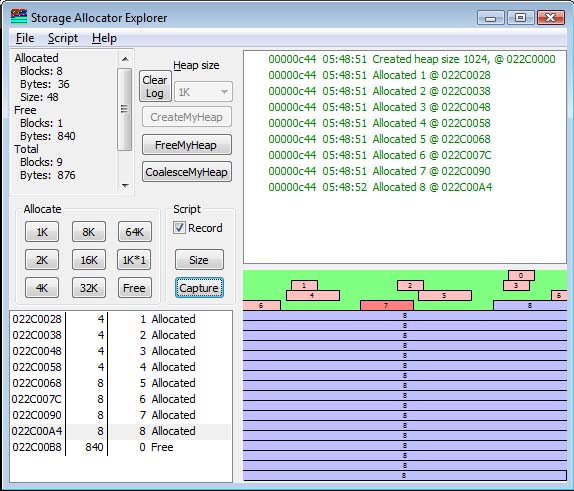
 Allocation
AllocationWhen a request comes in, the storage allocator locates a block suitable for the allocation, and returns a pointer to it. There are several different styles of doing this, such as "first fit", "best fit" and "quick fit". The allocator I show here is "first fit". The list of blocks is scanned until a free block large enough to satisfy the request is found. The block, if it is larger than the request, is "split" into two blocks; the first part is returned as the result of the allocation request, and the rest of it remains as a new, smaller, block on the free list. So if I have a 32K block at the front, and ask for a 1K allocation, the allocator does not search for a 1K free block, or the smallest-block-not-less-than-1K (this is "best fit") but simply splits the first block it finds that is large enough to satisfy the request, hence the name "first fit".
"Quick Fit" is an algorithm developed by Dr. Charles B. Weinstock as part of his research [Weinstock, Charles B. Dynamic Storage Allocation Techniques, Ph.D. dissertation, Department of Computer Science, Carnegie Mellon University, 1976] and later developed and tuned by me [Nestor, J. Newcomer, J. M., Gianinni, P. and Stone, D. IDL: The Language and its Implementation, Prentice-Hall, 1990]. What it does is keep a handy list of blocks of certain sizes and will allocate from these caches instead of performing a full allocation search.
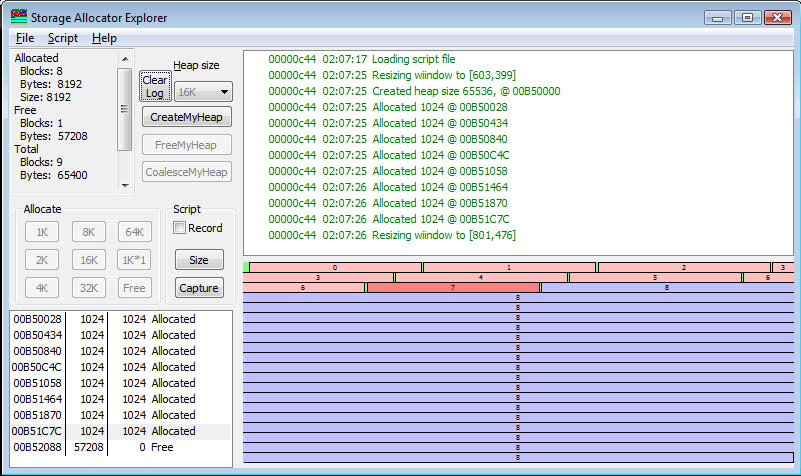
What is shown here is that I have clicked the 1K button 8 times, and performed eight allocations. In each case, the existing block (often called the "tail") is split into a 1K block and the rest-of-the-tail. So after 8 allocations, there are 57208 bytes left. Note that of the original 65,536 bytes, some went to the heap segment header, and some are consumed by the headers preceding each storage block. By looking at the top left, we see that the sum of the allocated space (8192) and free space (57208) is 65400. 136 bytes are "overhead". Note the small gap between segments (due to screen resolution issues, it appears to be different sizes, due to pixel roundoff errors). This represents the block header.
The block that is highlighted represents the block that is selected in the listbox on the left. Clicking on a block in the allocation map will select it, and right-clicking will bring up a menu which allows you to free the block if it is allocated.
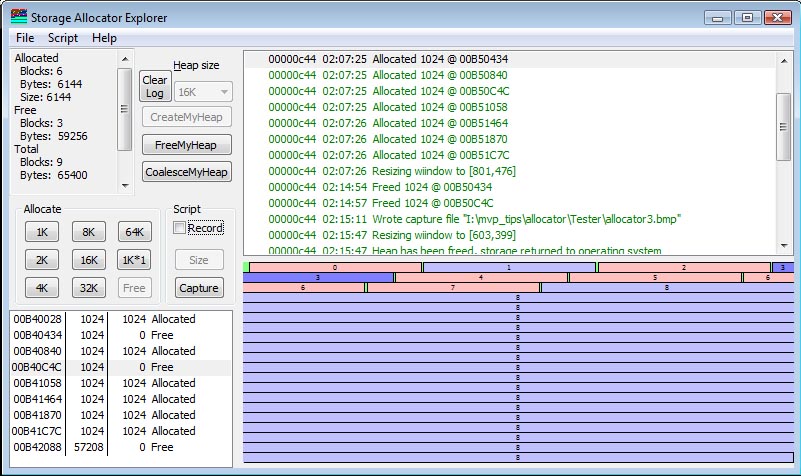
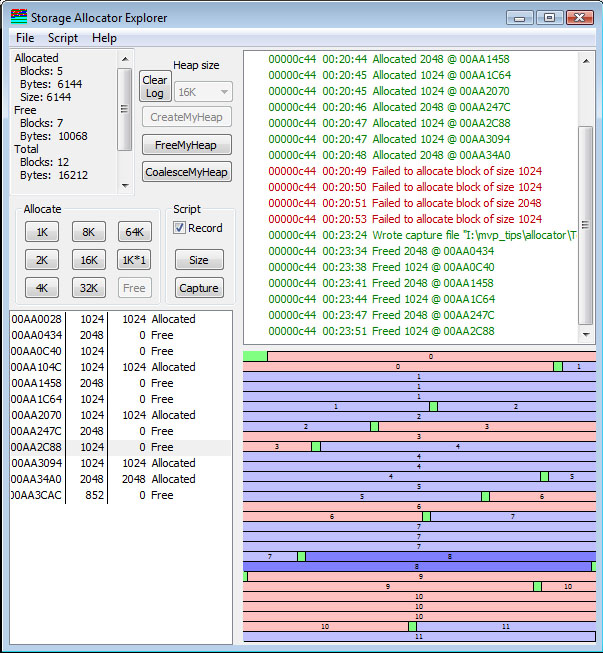
When a block is freed, it is marked as available. It is erroneous for the application to ever use the pointer to that block again for any purpose. The block is simply marked as "free" and ownership returns to the allocator. Under certain conditions, the free block may be coalesced with adjacent free blocks to form larger blocks.
It is good practice to set pointers to NULL after freeing the object they point to. This avoids using what is called a "dangling pointer" error, that is, a pointer to a block of memory which has been freed. Imagine if you have allocated a 100-byte block of storage, freed it, it coalesced with some other block, the space got reallocated, and then you write into the data structure you thought you once had a pointer to. You will corrupt either the control blocks used by the heap allocator, or corrupt data that legitimately is "owned" by some other part of your program now.
In the example shown above, I have clicked on two of the allocated blocks and freed them. I now have two non-adjacent free blocks. They cannot be coalesced.
Next, consider what happens if I free the block in between the two available blocks, as shown below:
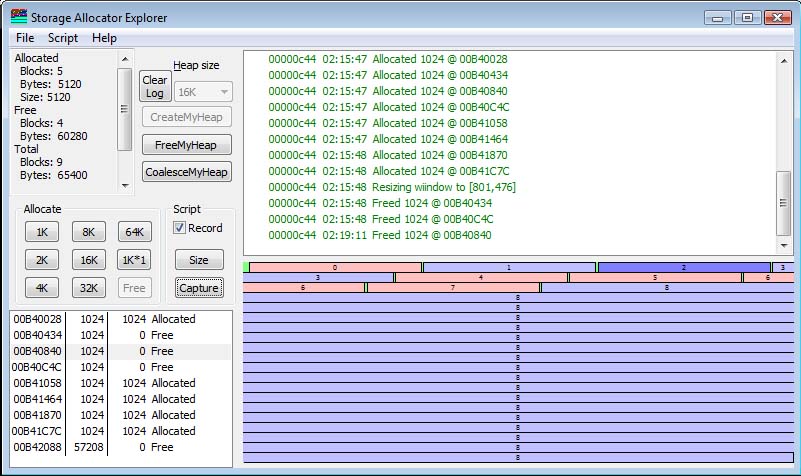
If I free the block in between them, what I end up with in this simple allocator is three 1K free blocks. If I want to do a 2K allocation, it cannot be satisfied from the existing space, and therefore will be allocated at the end (using "tail allocation") as shown in the next figure. Block #8 cannot fit into any space available, so it is allocated by first-fit out of the first available block large enough to satisfy the request.
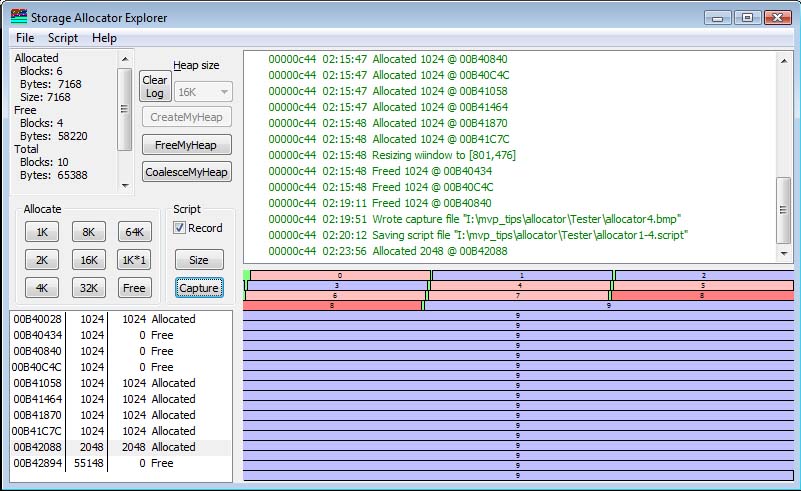
 Coalescing
CoalescingWhen a block is freed, and it is adjacent to another block, the two blocks can be combined into a single larger block whose size is the sum of the two block sizes plus the size of the header which has now been absorbed.
There are several approaches to coalescing. In aggressive coalescing, blocks are combined as soon as they are freed. If you free a block between two free blocks, the two free blocks are combined with the newly-freed block to form a single larger block. The simple allocator I do here does not do aggressive coalescing. For aggressive coalescing to work efficiently, a back-pointer to the previous block must be maintained. In lazy coalescing, blocks are not combined until an allocation failure occurs. Then adjacent blocks are coalesced. There are two forms of lazy coalescing: coalesce all and coalesce-until-satisfied. In coalesce all, the entire set of memory blocks are examined, and adjacent free blocks are coalesced, then the allocation is retried. If it fails after the coalesce, we have a different level of failure and respond accordingly (see Expanding the heap). In coalesce-until-satisfied, we start coalescing, and as soon as we have combined two blocks to make one that is large enough, we stop the coalescing and return a pointer to the block that has just formed (note that it might have been split, e.g., a 4K and 16K block combined into a 20K block, then split into an 8K allocated and 12K free pair of blocks). In QuickFit, coalescing of large blocks is usually aggressive, but coalescing of small blocks is lazy.
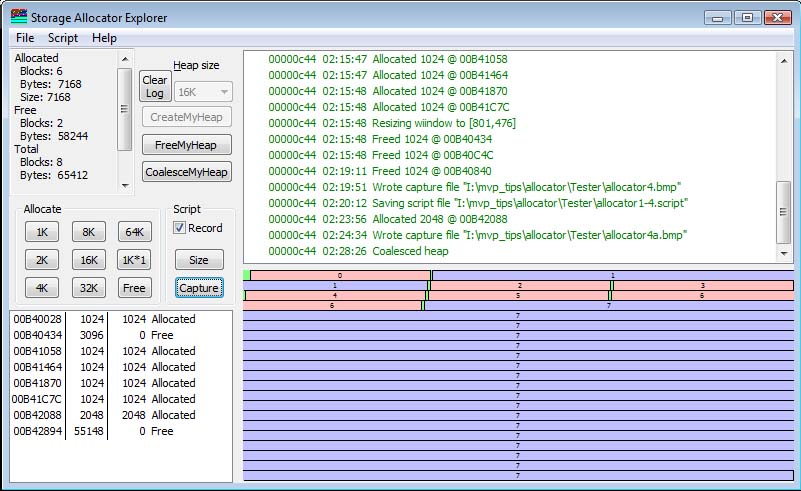
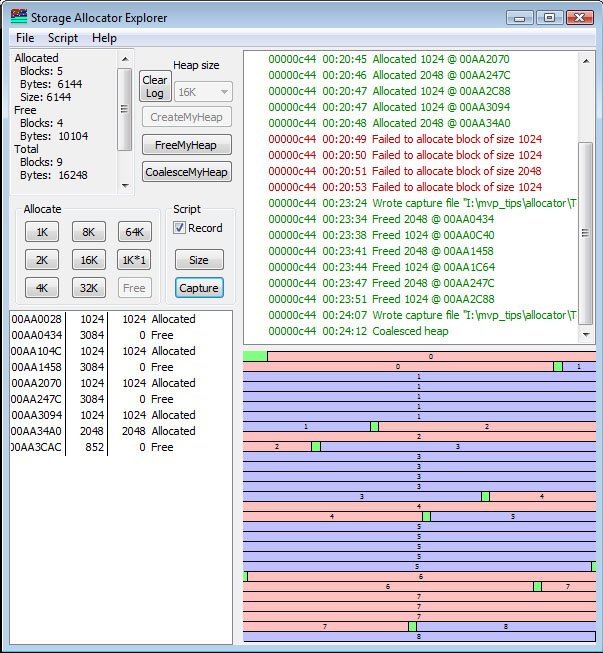
In my little allocator example, there is no implicit coalescing. Coalescing is not performed until a function is called to coalesce, and at that point the coalescing is done. By clicking the CoalesceMyHeap button, note that the three 1K blocks are now combined into a single 3096-byte block, which I clicked on to highlight for this illustration.
It is not 3072 bytes, as you might expect, from 3*1024=3072, but the two block headers, at 12 bytes each, became part of the block. So the block size is 3072+24=3096 bytes.
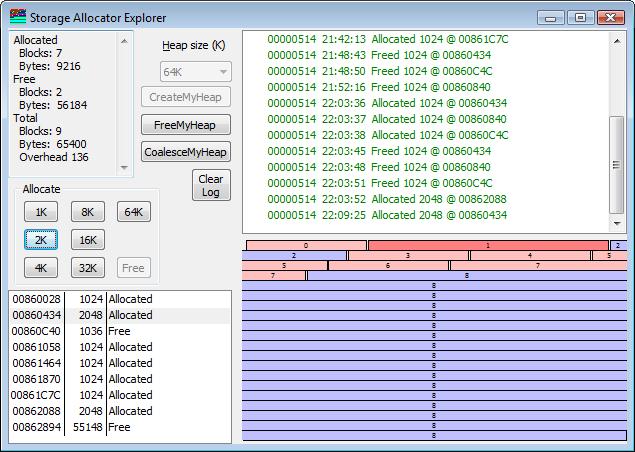 Now, if I do a 2K allocation, I will get
that block allocated in the front. This is the nature of the behavior of
First Fit. The highlighted block was allocated in the space of the former
3096-byte free block. Note that block 2 is now a 1024-byte block, the
result of splitting the existing block.
Now, if I do a 2K allocation, I will get
that block allocated in the front. This is the nature of the behavior of
First Fit. The highlighted block was allocated in the space of the former
3096-byte free block. Note that block 2 is now a 1024-byte block, the
result of splitting the existing block.
In the illustration of Freeing, two non-adjacent memory 1K memory blocks are freed. So if these were the only two free blocks, and there was a desire to allocate a 2K block, nothing would happen. While there are 2K bytes of "free" storage, they are non-adjacent, and therefore useless for this purpose.
One thing that would be nice would be to "slide" that third block down into the position of the second block, thus making the third block free; two adjacent 1K free blocks will coalesce into a single 2K free block, and the allocation would succeed. But the problem with doing this in a language like C or C++ is that there are pointers to this address (0x009E0840), and it would be necessary to find all the pointers to this block, cause them to point to the position of the second block (0x009E0343), move the block down, and then coalesce. But in languages like C/C++, there is no way the storage allocator can find all the pointers, since they could be in local variables, global variables, heap-allocated structures, and even temporary registers. And such transformations have to be thread-safe, which makes it essentially impossible to achieve.
Languages like Java, VB, and C# have very rich representations of information, and in fact it is possible in these languages to locate all the pointers, and manage them in a thread-safe fashion, so that heap compaction is possible.
The consequence of having "holes" in the heap that are not usable to satisfy a request is called Storage fragmentation or Heap fragmentation. It is often the consequence of having allocations of lots of different-size objects that have unusual lifetimes with respect to each other. Allocators like QuickFit are intrinsically low-fragmentation because they tend to re-use existing blocks of the precise size to satisfy requests. By reducing the need for block-splitting, the chances of getting these holes distributed around is lowered. On the other hand, First Fit is intrinsically a high-fragmentation algorithm. It doesn't matter if there are blocks further along in the heap that can satisfy the request; a larger block will be split. Best Fit historically had been the best approach to reducing fragmentation, but it requires potentially a complete search of the entire heap to first determine there is no precise match, before accepting the previously-recorded "best" match. The optimization is to keep the free-list sorted in order of ascending block size.
Look at the accompanying figures below. In Fragmentation-1, a small (16K) heap was created, and a sequence of blocks was allocated in the sequence 1K-2K-1K. In Fragmentation-2, the 2K-1K blocks have been freed, leaving the sequence
|| Allocated 1K || Free 2K || Free 1K ||
In Fragmentation-3, I have clicked the CoalesceMyHeap button and the blocks have been coalesced; we are left with the sequence
|| Allocated 1K || Free 3084 ||
Note that 1024+2048 = 3072, so how did I get 3084? Because a block header is 12 bytes, and the block header between the 2K and 1K blocks has now been added to the available free space.
In Fragmentation-4, I have allocated a sequence of 1K blocks. Note that there is now the sequence
|| Allocated 1K || Allocated 1K || Allocated 1K || Free 1012 ||
When the first allocation was done, the 3084 block is split into a 1024-byte block and a 2048-byte block. But when I do the second 1K allocation, the 2048-byte block is split into a 1024-byte block and a 1012-byte block, because the 12-byte header for the new free block must be taken from the available 1024 bytes. The result is when we are finished, and run out of space, we have several unallocated 1012 byte blocks. According to the statistics display (which is partially scrolled out of sight in the screen shot) the usage is
Allocated Blocks: 11 Bytes: 12288 Size: 12288 Free Blocks: 4 Bytes: 3888 Total Blocks: 15 Bytes: 16176 Size: 16176 Overhead 208 Padding 0
There are 11 blocks allocated; each allocated region is the exact size of the number of bytes it represents, so there are 12,288 bytes allocated consuming 12,288 bytes.
There are 4 free blocks. Their sizes are 1012, 1012, 1012, and 852, totaling 3888 bytes. Counting the heap segment header and the 15 block headers there are 15*12 bytes (180 bytes) of block header overhead, and 28 bytes of segment header overhead, so we have
65,536 - (12,288 + 3,888) = 208 = 180 + 28
The overhead is the "cost" of doing business with the allocator.
But there are 3,888 bytes of "unusable" space. While this should be enough to allocate three more 1024-byte blocks, no block is large enough. The blocks cannot be moved, and therefore the storage cannot be compacted.
This is why languages like Java and C# support storage compaction; all these allocated blocks would be moved down, creating a 3,888-byte "tail", which would be able to handle larger allocations.
In the case of C/C++, we have run out of space, even though we have been freeing objects all along. Free space is not necessarily usable free space.
Some years ago, Jim Mitchell (now a VP of research at Sun) invented an algorithm for our project at CMU. He kept a running mean-and-standard-deviation of storage allocations. This was expensive, because he kept it in float, which was very slow on the architecture we were using. What he did was apply this knowledge each time a block split was required. If the result of the split that was a block smaller than the mean minus one sigma (standard deviation), he did not split the block, because the resulting fragment would very likely not be usable. This reduced our fragmentation. Another misfeature of fragmentation is that we are obliged to look even at the useless fragments while searching for a first-fit or best-fit situation, so it increased performance. The performance improvement offset the cost of maintaining floating-point computations one each allocation.
 |
 |
| Fragmentation-1: Allocated blocks: (1K-2K-1K)* | Fragmentation-2: Freed the 2K-1K part |
 |
|
| Fragmentation-3: Blocks coalesced, creating several 3084-byte free blocks | Fragmentation-4: Allocating 1K blocks |
A question came up, "I want to allocate a lot of small blocks and I run out of space. The blocks are all 1 byte long." So I show that in my allocator. Indeed, in a 1K heap, I can allocate 61 bytes.
Why is it that I cannot allocate more than this rather small number of blocks of 1 byte each? The answer is that a 1-byte block requires a very large number of bytes. In the case of the C/C++ runtime, there is a substantial overhead for the block header, and there are 7 "wasted" bytes because all allocations are on 8-byte boundaries. In my Allocation Explorer, I added a 1K*1 button that tries to allocate 1024 1-byte blocks. If my heap is only 1K, I can get 61 allocations.
Note that the size of the allocation, which is 4 bytes, is completely swamped by the overhead of the block header. According to the statistics,
Allocated Blocks: 61 Bytes: 61 Size: 264 Free Blocks: 0 Bytes: 0 Total Blocks: 61 Bytes: 61 Size: 264 Overhead 760 Padding 203
there are 61 blocks allocated, representing 61 bytes of information, but the "Chunk" size, in this allocator, 4 bytes, is 4*61=244 bytes. Hmmm... that's different than the 264 bytes the stats tell me (more on this in a moment!) There are 760 bytes of "overhead" representing the headers, and 203 bytes of "Padding" required to round the allocation up to the next allocation boundary.
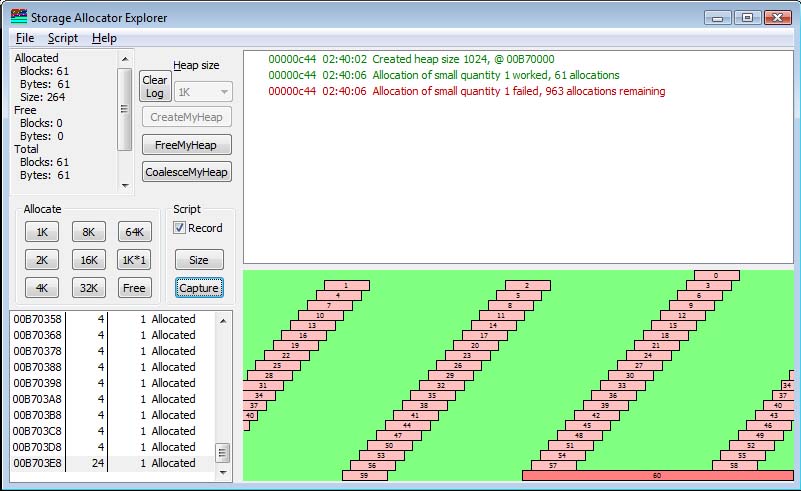
Pay particular attention to the last block. While all the other blocks are of size 4 to hold the data (with 12-byte overhead), the last block is of size 24. Why should that be so? Well, it turns out there is a parameter that says whether or not a block should be split. Because of how I set it (see the code I give later), an attempt to split the last block will result in a block smaller than this threshold, and so the allocator will not split the block. Changing this value will change the behavior of this code. Whether or not this is a Good Change depends on the nature of the problem domain that is using the allocator. But the issue here is to show that the useful space allocated is substantially smaller than the overhead required to manage it! But this explains why the number of bytes allocated is larger than 61*4 would suggest, because the 61*4 number assumes that there is "perfect splitting" and every small request will split a larger block, even if the result is too small to be usable in the future. (The last block had been 24 bytes in length. If split, it would create one 4-byte block, leaving 20 bytes to be allocated in the future. This 20 bytes, however, would also require a header of 12 bytes, leaving actually only 8 bytes of usable storage. I set the split threshold to 16, so because of this, the last block left would be smaller than my minimum block size after a split, and therefore it was not split).
So now the answer to how, given a 1K heap, I could allocate only 61 1-byte objects from it. The problem, of course, is those overhead bytes. They are killers. They can completely swamp any allocation you do of small objects.
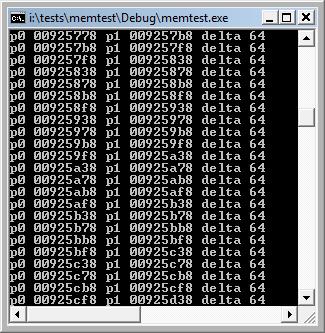
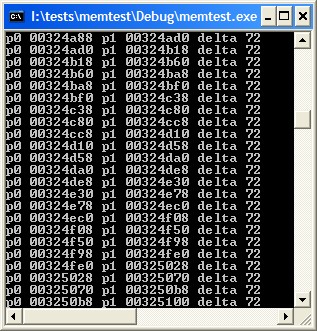
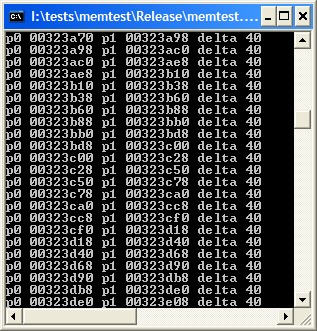
To show the nature of the overhead in the C/C++ runtimes, I wrote a little program which is shown below. I collected data for VS2008 in both Debug and Release configurations. For VS2008, the values were 64 bytes required to allocate 1 byte of data in Debug configuration, and 32 bytes in Release configuration. In VS6, the corresponding numbers were 72 for Debug and 40 for Release. What surprised me, and ultimately led to this article, was the fact that the person who asked the question seemed genuinely surprised by the answer. This told me that there is very little understanding out there about how allocators work.
#include "stdafx.h" #include |
 |
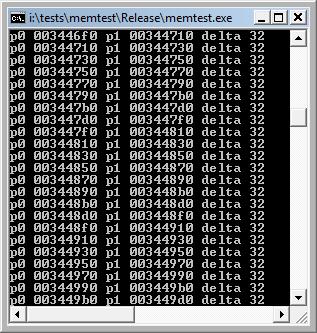 |
| Visual Studio 2008, Debug configuration | Visual Studio 2008, Release configuration | |
 |
 |
|
| The program | Visual Studio 6, Debug configuration | Visual Studio 6, Release configuration |
If I had a 1K block left in the C runtimes, I could only allocate the number of blocks shown in the table.
| Platform |
1-byte allocations per 1K block |
| VS 2008, release | 32 |
| VS 2008, debug | 16 |
| VS6, release | 25 |
| VS6, debug | 14 |
| Custom allocator | 896 |
There is nothing that precludes you from creating your own "small block" allocator. For example, you could have a sequence of 36 bytes. The first DWORD is a "bit map availability' marker, and a 1-bit indicates a byte is allocated and a 0-bit indicates the byte is free. The remaining 32 bytes are the single-value values to be allocated.
To allocate a single byte, you walk the array of the struct, searching for any block which has free elements. Then you locate the free element with a simple bit-shift operation (there are even machine instructions you could use to do this in a single instruction!), mark that bit as in use, and return a pointer to its corresponding element in the 32-byte array that follows.
#pragma once
class ByteManager {
protected:
class ByteBlock {
public:
DWORD allocated;
BYTE data[32];
ByteBlock() { allocated = 0; }
};
typedef ByteBlock * PByteBlock;
public:
ByteManager(SIZE_T sz) { elements = sz; blocks = new ByteBlock[count(sz)]; }
virtual ~ByteManager() { delete [ ] blocks; }
LPBYTE Alloc();
void Free(LPBYTE p);
SIZE_T size() { return elements; }
protected:
SIZE_T count(SIZE_T n) { return ((n + 31) & ~(32 - 1)) / 32; }
SIZE_T elements;
PByteBlock blocks;
};
In this very simple example, there is no provision made to allocate more bytes, because we cannot perform any operation that would cause an internal reallocation of the vector.
The ability to allow dynamic resizing of the structure could be added by returning not an actual pointer, but a "reference object" that has the property that you can use it with Set and Get operations. Imagine returning a packed binary number, where the low-order 5 bits were the index into the 32-byte data array and the high-order 27 bits were the index into the blocks vector. Then std::vector<ByteBlock> could be used, and if you exhaust the available space, just resize() to a larger size. This is left as an Exercise For The Reader.
#include "stdafx.h"
#include "ByteManager.h"
/****************************************************************************
* ByteManager::Alloc
* Result: LPBYTE
*
* Effect:
* Allocates one byte, or returns NULL if nothing can be allocated
* Notes:
* This uses a bit allocation map, 32 bits to allocate 32 bytes
* A 1-bit in the bit allocation map means the byte is allocated
* A 0-bit in the bit allocation map means the byte is free
* This handles an array of bytes
****************************************************************************/
LPBYTE ByteManager::Alloc()
{
for(SIZE_T i = 0; i < count(elements); i++)
{ /* search for free block */
if(blocks[i].allocated == 0xFFFFFFFF)
continue; // all bytes allocated
for(SIZE_T n = 0; n < 32; n++)
{ /* search for free byte */
if((blocks[i].allocated & (1 << n)) == 0)
{ /* allocate free */
blocks[i].allocated |= (1 << n);
return &blocks[i].data[n];
} /* allocate free */
} /* search for free byte */
} /* search for free block */
return NULL;
} // ByteManager::Alloc
/****************************************************************************
* ByteManager::Free
* Inputs:
* LPBYTE p: Byte to free
* Result: void
*
* Effect:
* Frees the byte
****************************************************************************/
void ByteManager::Free(LPBYTE p)
{
SIZE_T index = (p - (LPBYTE)blocks) / sizeof(ByteBlock);
SIZE_T shift = (p - (LPBYTE)&blocks[index].data[0]);
blocks[index].allocated &= ~(1 << shift);
} // ByteManager::Free
The overhead for the above implementation is one bit per single byte allocation; that is, 1:8 overhead (not counting the fixed overhead of the structure instance). But if a general allocator is used for this purpose, the ratio is at worst 72:1 and at best 32:1. (Take particular note of the way these ratios are expressed; the ByteManager is somewhere between 576 and 256 times more space-efficient than the general allocator!) This shows that it is possible to create specialized allocators that have significant performance improvement (in space) over general allocators. It is also the case that this particular allocator could have significant performance improvement in time, as well. With optimization (such as not having to search fully-occupied blocks) it would definitely have significant performance improvement.
One simple optimization that could be added would to be avoid searching the "front" of the structure for free blocks if the nature of the operations is that deletions are rare. With the addition of a "LowestAvailable" index variable, initialized to 0, that search time for a free block can be optimized. The test for a free block could be modified to be
for(SIZE_T i = LowestAvailable; i < count(elements); i++)
{
if(blocks[i].allocated == 0xFFFFFFFF)
{ /* fully allocated */
if(front_scanning)
LowestAvailable = i;
continue;
} /* fully allocated */
front_scanning = FALSE;
In the Free routine, if an element is freed, LowestAvailable is set to the min of LowestAvailable and the index which contains the newly-freed element. Other details are left as an Exercise For The Reader.
In C and C++, we work by doing explicit allocation and deallocation. Every malloc must have a corresponding free and every new must have a corresponding delete While concepts like "smart pointers" give an illusion of garbage collection, they are not garbage collection in the true sense of the term. A "smart pointer" is just a reference-counted pointer that implicitly does a delete when the last reference to an object is deleted. This is very useful in helping write robust and reliable code, but is not actually a substitute for true garbage collection.
The simplest way to explain garbage collection is by explaining the mark-and-sweep model. In mark-and-sweep, you start at a known root, or set of roots, and follow all pointers reachable from that set of roots. Each time you follow a pointer into an object, you mark the object, then follow all the pointers in it to all the items it points to and mark them. Lather, rinse, repeat. If you follow a pointer and find a marked node, you can stop marking because some other pass has already marked that node and all nodes reachable from it. When you have run out of roots to start at and therefore all the nodes have been marked, you then make a linear pass (the sweep) across all of memory, looking at each object. If it is marked, it is in use. If it is not marked, it means that nobody is referencing it, and it can be deleted. This classic algorithm was developed in the late 1950s to support the LISP language. You can read extensively about garbage collection in Wikipedia.
In one LISP implementation I am familiar with, the "roots" consisted of a few global variables in the LISP interpreter, and by convention any pointer found in some designated registers. It was essential in writing machine-code extensions to LISP, or executing compiled LISP code, that any pointers to LISP cells that might not be reachable from the normal roots during temporary computations must be in one of these registers (and they could never be used for non-pointer values!) to guarantee that the garbage collector could find all the nodes. In C/C++, there are no such conventions of where all pointers can be found, and therefore it is impossible to implement general garbage collection. However, in specific restricted cases, true garbage collection can be implemented when a known set of roots and the structures that contain the pointers are known. You can build your own garbage-collected heap, as long as your follow your rules and make sure you know where all the pointers are into your heap. But you can't generalize this to working with arbitrary structures in the normal heap of any C/C++ environment.
Note that if you use C++ with the Common Language Runtime (CLR) the CLR heap is garbage-collected. However, there are numerous rules you must follow so this works correctly in all cases.
A form of garbage collection can be implemented using reference counting. With reference counting, every object holds a count of how many objects are referencing it. When a reference is removed, the reference count is decremented; when a reference is created, the reference count is incremented. Operations such as parameter passing will increase the reference count. Returning from the subroutine will decrease the reference count. Reference counting is aggressive garbage collection in that as soon as a reference count goes to zero, the object is deleted. Deleting the object will delete any pointers it has, and the deletion of these pointers will decrement the reference count of the objects pointed to, and this in turn may cause those objects to be deleted, and so on. Contrast this with ordinary garbage collection, which is lazy evaluation; generally mark-and-sweep style garbage collection is not invoked until you run out of storage. This requires a substantial amount of time in complex systems, because it can also trigger massive numbers of page faults as every page in the heap is touched during the gc mark and then again during the gc sweep. This can result in a noticeable service interruption. Reference-count garbage collection usually has a distributed overhead that does not introduce massive pauses and usually doesn't trigger massive page faulting sequences.
One way of implementing reference counted garbage collection is with smart pointers. If every object that has pointers uses only smart pointers inside it to reference other objects, and all pointers that reference the object are themselves smart pointers, then a smart-pointer reference-counted garbage collector will work. However, the usual downside of reference-counted systems is that if you get a disconnected cycle of objects such that A references B, B references C, and C references A, then you get a situation where, while none of the objects are reachable, internally self-consistent structures all have non-zero reference counts on every object, so the nodes will never be freed. However, as a practical matter, many useful structures have no cycles. Linear linked lists, trees, and in general any directed acyclic graph (DAG) structure can withstand reference-counting, providing you have a smart pointer to the root or roots of the structure(s).
When there are no more blocks to be allocated, there are several approaches. If the coalescing has failed to produce a block of sufficient size, one approach is to return NULL or throw an exception indicating that the allocation request could not be satisfied. Some allocators will call upon the operating system to allocate another large block of storage, and in one of the the heap segments (typically the first one) put a pointer in the heap segment header to the new block of storage, and in essence create a linked list of these heap segment which are then split and subdivided as necessary. The reason for putting the pointer into the first heap segment is that the other segments have failed, so it is likely that the new segment should be searched first for available blocks. Sometimes the base heap segment pointer points to the newly-allocated heap segment directly, and the new heap segment's header points to the previous first heap segment.
Other allocators will not do this (the simple allocator shown here will not create secondary heap segments). These large blocks are allocated by calling upon the operating system to provide additional address space. If that allocation fails, you are simply out of memory and you will have to deal with this as best you can. When it comes to asking the operating system to create these large heap segments, very often there is a loop that attempts to allocate a BIG chunk of memory, then a Big chunk of memory, then a big chunk of memory, then a MEDIUM chunk of memory, ... and so on, until as a last resort it tries to obtaining a block of address space just big enough to hold the requested size object (the smallest potential allocation might be as small as a single kernel allocation granularity, nominally 64K on an x86-based 32-bit Windows machine), and not give until even that tiny request is unsatisfiable.
In addition, if you call on ::VirtualAlloc to give you more address space, it typically wants to commit the pages. This means that the pages are brought into existence, not just in your address space, but as actual physical pages of data. This means that there has to be a place to put them (such as the paging file). If your disk is close to full, there may be no way to expand the paging file to accommodate these new pages. In such a case, ::VirtualAlloc will fail. You may have used only 512MB of your potential 2GB partition, but still get a "system has run out of memory" error. Yes, you have run out of memory. In spite of the fact that your process is nominally entitled to use up to 2GB (or 3GB if booted in that mode), there is no guarantee that the system will be able to supply this number of pages, because of paging space limitations. You will have to reconfigure for a larger paging file and reboot.
A common question that comes up is "I allocated <N> objects, freed them all, and my program didn't get any smaller? What's wrong?" Generally, what's wrong is that they are trusting useless tools like Task Manager or Process Explorer to account for their memory. This is not practical. All these tools do is tell you how much address space is in use, not how much of that address space is being actively used. Furthermore, it is exceedingly rare to have an allocator that will release a heap segment back to the operating system. This is so rarely possible that most allocators (including the simple allocator shown here) don't even consider it a possibility.
Note, for example, in the very first figure, where all of the memory is free, as far as the operating system is concerned, and that means as far as Task Manager and Process Explorer is concerned, all of that memory is in use! The fact that not a single object has been allocated in it is irrelevant. The address space is committed to the process, and therefore the memory is in use. This is why Task Manager and Process Explorer are completely useless for telling what your process is doing in terms of allocation. If you allocate a million strings, if they are 1-character strings, each 1-character string requires 72 bytes in the debug version of the Visual Studio 2008 runtime, and 40 bytes in the release version. But if you then free all million strings, as far as the operating system is concerned, your process still owns 72 megabytes of data, and will do so in perpetuity, until the process terminates. This space will never be released to the operating system. Any numbers that indicate that usage have diminished are most probably due to trimming of the working set, reducing the total page count that the process is allowed to have resident at any one time. Which is another of the many reasons that these numbers cannot be trusted. They are not telling how much address space your process is using; they are telling how much address space is currently resident in memory, which has nothing to do with how much address space is in use, or how much of it represents objects that are currently allocated from that address space.
Consider the illustration below. There are only two blocks in the allocator: a large one at the front, 65464 bytes in size. And a small one at the end, a 20-byte block representing the allocation of a single byte of information. Note that as long as there is any allocated block in the segment, no matter how small (and in fact, no matter where it is), the segment cannot be released to the operating system. Furthermore, even if we could release a piece of the storage back to the operating system, we cannot do so without massive complexity being added; for example, we would have to split the heap into two segments: that segment which precedes the released storage, and that segment which follows. We would have to add flags saying "there is a potentially large block here of thus-and-such-a-size but you have to call the operating system to get real pages back". All of this would simply add to what is already a somewhat expensive allocation mechanism, and therefore it is not done. So while Task Manager would count the entire 64K block as being "in use", in fact, almost none of it is in use as far as your program is concerned. Relying on the Task Manager or Process Viewer to tell you this will give you misleading information; it will not tell you how much memory your program is using, it will tell you how much address space is allocated to your program. It is essential that you understand the difference between the two concepts, and realize that very little of what Task Manager or Process Viewer is telling you has much relevance to reality. The only really interesting thing it can tell you is that if it consistently tells you that your address space is growing, there is very possibly a memory leak. Or maybe you just have to allocate a lot of storage which is legitimately being used! Or maybe your storage is getting very badly fragmented. Unfortunately, the two tools most commonly used to produce bad interpretations of the data are going to give you no help in determining what has really gone wrong if your program is consuming massive amounts of storage.
Ideally, this will now show why a buffer overrun is fatal. In a real allocator, certain consistency checks, which I did not bother to implement, are performed on storage headers. In one operating system, we actually put a duplicate header at the end of each block, with the pointers swapped (that is, a 32-bit pointer of two 16-bit values <A, B> was stored at the end of the allocated block in the format <B, A> and the allocator regularly checked that the "trailers" matched the "headers" after accounting for the swapping.
A common question we get is "I'm getting some kind of crash in the storage allocator". Sorry, but the language is usually that sloppy. It isn't a "crash", it is an "exception", and it is usually 0x80000003, meaning "A breakpoint was hit". This indicates you have corrupted your heap, but in a fashion that the allocator was able to detect and report. You have a bug. Fix it. If it is 0xC0000005, it is an access fault, usually caused by corrupting the allocator's equivalent of our next pointer.
If you have a memory overrun, you will most damage the storage headers of the block that follows you. In particular, note that the flag that says it is allocated may be accidentally set to the incorrect value (marking n allocated block as free, or a free block as allocated), the next pointer is damaged, or the size is damaged. In this trivial allocator, these will have seriously fatal consequences. In real allocators, the double-checking and cross-checking that goes on (particularly in the Debug versions of the program) will try to catch these errors earlier and give a meaningful report about them. Note that a 1-byte overrun may have no impact on a 5-byte, 6-byte, or 7-byte allocation because allocations are quantized to some value (in the Microsoft CRT, 8 bytes,. in my allocator, 4 bytes). because the overrun falls into the area which is not actually "in use", but the same error on an 8-byte allocation will clobber the first byte of the header that follows. So sometimes these errors do not always show up, particularly when they are the classic off-by-one allocate-a-string-buffer-but-forget-to-allow-for-the-NUL-byte.
Tools such as the Application Verifier get their fingers into the low-level storage allocation mechanisms of the process they monitor. If you allocate a block, no matter how small, it is arranged so it is allocated at the end of a page instead of from the general heap. The allocation is aligned to the appropriate boundary (in Windows, 8-byte), and the "tail" of the space, usually designed by a term like residual space, is filled with a known pattern. So if you allocate 1, 2, 3, 4, 5, 6 or 7 bytes of storage, it will be at the end of a page with 7, 6, 5, 4, 3, 2, or 1 bytes of filler (generalize for 8*n+1, 8*n+2, etc.), followed by a nonexistent page. If you have a gross overrun, you will get an access fault as your program continues after the end of the page and tries to write to the nonexistent page. At various times, such as deallocation time, the filler is checked to see if it has been damaged. If it is intact, your use of the memory was valid. If it is trashed, you had a very slight memory overrun, but nonetheless an error, and it will be reported to you. The debug heap in the Microsoft C runtime will report errors if the residual space has been written. It will also test the integrity of the pointer, size, and flag information in the block headers.
To create an allocator that is useful in a multithreaded environment, a lock must be provided. Any operation on the heap must first set this lock to prevent other threads from working on the heap at the same time, and of course the lock must be released when the operations are complete. The problem with this is that the lock now becomes a performance bottleneck. When running on a high-order multiprocessor (for example, say, 64 CPUs), if all 64 CPUs go after the lock (using InterlockedCompareAndExchange as a typical example), there is a massive amount of interbus traffic, tying up the interprocessor busses of a NUMA architecture. In addition, since only one CPU at a time can perform an operation on the heap, all the CPUs that want to allocate are forced to execute in sequence, with no concurrency possible. Thus there is a performance loss caused by all the CPUs trying to allocate at once. In general, most applications do not have a massive number of threads doing intensive allocation, so statistically such bottlenecks are rare. For systems which are memory-intensive, however, the way this is typically handled is to have local heaps which are unique to each thread. Thus, no locking is required and there are no lock conflicts. However, it means that when using the positive-handoff protocol pattern for passing pointers around among threads, provision has to be made to make sure that the pointer to the object to be deleted is passed back to the owning thread because it, and it alone, is permitted to access the heap from which that storage block was obtained.
Note that this toy allocator, if you remove the locking, you have a non-thread-safe allocator, that can be used by at most one thread. In addition, you could use VirtualAllocExNuma to allocate memory on specific NUMA nodes so the heap is not only local to a thread, but it is even local to the node which is local to the CPU.
We simplify this allocator by simply not allowing any free operation or delete operation. You can allocate, but when you run out of memory, it is all over. However, you can reset the pointer to any heap address previously returned. This is called a "mark-and-release" allocator, and was popular for years in Pascal systems.
It has the advantage of not only being simple, but blindingly fast.
This is used in situations where you need to allocate a lot of storage, use it, and free it all, or do so in a nested fashion. For example, this can allocate a lot of space, but frees it up before the function returns
void MyFunction(...)
{
LPVOID mark = GetMyHeapPointer();
while(TRUE)
{
... = AllocMyHeap(...);
}
FreeMyHeapTo(mark);
}
The code for the allocator is trivial:
MyMarkRelease.cpp:
LPVOID Heap; SIZE_T Size; LPVOID Current; SIZE_T Count;
BOOL CreateMyHeap(SIZE_T size)
{
Current = Heap = VirtualAlloc(NULL, size, PAGE_COMMIT | PAGE_READWRITE);
if(Heap == NULL)
return FALSE;
Count = Size = size;
return TRUE;
}
LPVOID GetMyHeapPointer()
{
return Current;
}
LPVOID AllocMyHeap(SIZE_T n)
{
if(n < Count)
{ /* allocate */
Count -= n;
LPVOID result = Current;
Current = (LPBYTE)Current + n;
return result;
} /* allocate */
else
return NULL;
}
void FreeMyHeapTo(LPVOID p)
{
Current = p;
Count = Size - (SIZE_T)((LPBYTE)p - (LPBYTE)Heap)
}
The fundamental problem of mark-release allocators is that no object can have a lifetime beyond the release point. So you typically cannot call a function that calls a function that...calls a function that allocates an object that needs to exist for the life of the program. While mark-release may have been satisfactory for first-month programmers writing toy programs in a toy language (e.g., Pascal), it is generally not practical for most instances of real programs. (That said, Dr. Nigel Horspool, of the Computer Science Department of the University of Victoria in British Columbia, wrote a parser that parsed a million lines a minute of C or other code on a 68030-based Macintosh. One way he got performance was to recognize that after the parse tree has been built and the code generated, the entire parse tree can be freed. Therefore, a simple mark-release allocator for parse tree nodes was blindingly fast, and did all that was needed. Similar arguments could be made about reading XML files these days).
What I'm giving here is the simplest thread-safe storage allocator I could write. Its purpose is primarily tutorial, to illustrate what storage allocators do. It is not meant to be robust, bulletproof, aid debugging, detect memory leaks, or any of the things that serious allocators do. However, note that even allocators such as are found in the C Runtime Library will provide functionality akin to this allocator in very similar ways. The hope is that by studying the way this works, the mysteries of storage allocation will be no longer mysteries.
If you want the world's second-simplest storage allocator, remove the locks, and don't use it in a multithreaded environment.
In addition to the basic allocation, I will add a function that allows me to walk across the entire heap. This function is actually a bit complex, and would not fit my description of a "simple" storage allocator, so I consider it an add-on that I did for purposes of creating the pretty pictures for this Web page and for doing the "algorithm animation" program which is the Memory Allocation Explorer.
HANDLE CreateMyHeap(SIZE_T size) |
Allocates storage from the operating system to
hold the heap.
Parameters: size the maximum number of bytes available in the heap, which will include all overhead. The heap will not expand once this space is exhausted. Result: A heap handle. Remarks: The heap handle will be passed in to subsequent heap operations to designate which heap is being acted on.
|
LPVOID AllocMyHeap(HANDLE heap, SIZE_T size); |
Allocates a block from the heap Parameters: heap The handle to a heap created by CreateMyHeap. size The desired allocation, in bytes Result: A pointer to the storage which has been allocated. Returns NULL if the request could not be satisfied from the heap.
|
void FreeMyHeap(HANDLE heap, LPVOID addr); |
Frees a block of storage that had been
allocated by AllocMyHeap. Parameters: heap The handle to a heap created by CreateMyHeap. addr A pointer to a block of storage allocated by AllocMyHeap. Remarks: Frees the block of storage. Does no coalescing of the heap.
|
void CoalesceMyHeap(HANDLE heap); |
Coalesces adjacent free blocks within the heap. Parameters: heap The handle to a heap created by CreateMyHeap. Remarks: If there are no adjacent free blocks, this will have no effect.
|
void DestroyMyHeap(HANDLE heap); |
Releases the space used by the heap back to the
operating system Parameters: heap The handle to a heap created by CreateMyHeap. Remarks: It is the responsibility of the caller to make sure that there are no pointers into the space occupied by the heap. Such pointers will be rendered invalid when the heap is freed, and an attempt to access data using them will likely cause the program to terminate on an access fault. |
| The header file: allocator.h | |||||||||||||||||||||||||||||||||||||||||||||||||
#pragma once HANDLE CreateMyHeap(SIZE_T size); LPVOID AllocMyHeap(HANDLE heap, SIZE_T size); void FreeMyHeap(HANDLE heap, LPVOID addr); void CoalesceMyHeap(HANDLE heap); void DestroyMyHeap(HANDLE heap); |
Note that if you look at the actual project,
you will find a couple other methods and a structure prototyped; these are
used by the display program to show the block information, and are not part
of the functionality of the minimal storage allocator. So they are not
discussed in this article. They would not be required to build a real
allocator, and are only necessary for the graphical presentation.
|
||||||||||||||||||||||||||||||||||||||||||||||||
| The precompiled header file stdafx.h | |||||||||||||||||||||||||||||||||||||||||||||||||
#pragma once #include "targetver.h" #define WIN32_LEAN_AND_MEAN // Exclude rarely-used stuff from Windows headers #include <windows.h> |
This is standard boilerplate in stdafx.h. | ||||||||||||||||||||||||||||||||||||||||||||||||
| The implementation file allocator.cpp | |||||||||||||||||||||||||||||||||||||||||||||||||
| #include "stdafx.h" #include "Allocator.h" |
|||||||||||||||||||||||||||||||||||||||||||||||||
|
/**************************************************************************** * Storage Header Structures ****************************************************************************/ |
|||||||||||||||||||||||||||||||||||||||||||||||||
#define ALLOCATION_QUANTUM 4 // Changes will require changes in the structs below
typedef struct {
SIZE_T size;
CRITICAL_SECTION lock;
} SegmentHeader;
typedef struct {
SIZE_T size; // physical size of block
SIZE_T allocated; // allocated size; 0 means free
LPVOID next;
} BlockHeader;
// Note that the above headers *must* be an integer multiple of allocation quantum
// This simple allocator requires adding filler by hand if ALLOCATION_QUANTUM changes
|
The ALLOCATION_QUANTUM determines two
characteristics of the allocator: the smallest block of memory that can be
allocated, and the alignment of the memory. The choice here is to
allocate no smaller than a 4-byte quantity, on a 4-byte boundary.
The SegmentHeader is at the front of a heap segment. This is a very small header, containing the minimum amount of information required to perform allocation and freeing. Because freeing requires knowing how big the heap is, we store that value in the segment header. To avoid problems in multithreaded systems, we put a CRITICAL_SECTION here which is used to perform mutual exclusion if multiple threads attempt to use the heap at the same time. The BlockHeader is used to describe blocks within the heap. The size is the actual size of the allocation for allocated blocks, and the size of the free space for free blocks. Note that for allocated blocks, size can be any value, but for free blocks it is always a multiple of the ALLOCATION_QUANTUM. The allocated flag tells if the storage is allocated. It is TRUE if the block is an allocated block and FALSE if the block is a free block. The next pointer points to the next block. Note that these structures do not appear in the header file because their very existence is private to the implementation of the allocator. Therefore, it would inappropriate to put these in the public header file. In a C++ world, the header file would define an interface that exposed the minimum number of concepts; a good interface has no private or protected members, or data definitions, only public methods. |
||||||||||||||||||||||||||||||||||||||||||||||||
/****************************************************************************
* ALLOCSIZE
* Inputs:
* SIZE_T n: Size of allocation requested
* Result: SIZE_T
* The actual size to allocate
* Notes:
* It is rounded up to the next allocation quantum
****************************************************************************/
|
|||||||||||||||||||||||||||||||||||||||||||||||||
static __inline SIZE_T ALLOCSIZE(SIZE_T size) { return (size + (ALLOCATION_QUANTUM - 1)) & ~(ALLOCATION_QUANTUM - 1); } // ALLOCSIZE |
This internal function is used to round up a
size to the next allocation boundary. This relies on some interesting features of 2's complement arithmetic. For example, if a value n is a power of 2, then a mask that truncates all the bits and rounds down to the multiple-of-n boundary is computed as ~ (n - 1).
|
||||||||||||||||||||||||||||||||||||||||||||||||
/**************************************************************************** * CreateMyHeap * Inputs: * SIZE_T size: Desired size of heap, in bytes * Result: HANDLE * Heap handle, or NULL if allocation failed * Effect: * Creates a heap ****************************************************************************/ |
This illustrates a way of
creating an "opaque" data type. A "HANDLE" is a very neutral
type of object; you can't treat it as a pointer, you can't look inside it,
you can't do anything with it except pass it in to the functions that
require this type of object. If I wanted to be more general, I would have added to allocator.h the declaration DECLARE_HANDLE(MYHEAPHANDLE); and used this type where I used the HANDLE type, but I decided to just go for the simple representation. |
||||||||||||||||||||||||||||||||||||||||||||||||
HANDLE CreateMyHeap(SIZE_T size)
{
if(size == 0)
return NULL; // silly request, ignore it
LPVOID mem = ::VirtualAlloc(NULL, size, MEM_COMMIT , PAGE_READWRITE);
if(mem == NULL)
return NULL;
//****************************************************************
// +----------------+----------------+---...
// | size | lock | ...
// +----------------+----------------+---...
// ^
// |
// seghdr
//****************************************************************
SegmentHeader * seghdr = (SegmentHeader *)mem;
seghdr->size = size; // size specified for creation
InitializeCriticalSection(&seghdr->lock);
BlockHeader * blockhdr = (BlockHeader*)&seghdr[1];
//***************************************************************************************
// +-------------+-------------+-------------+----------------+-------------+---...
// | size | lock | size | allocated | next | ...
// +-------------+-------------+-------------+----------------+-------------+---...
// ^ ^
// | |
// seghdr &seghdr[1]
// blockhdr
//***************************************************************************************
blockhdr->size = size - (sizeof(BlockHeader) + sizeof(SegmentHeader));
blockhdr->allocated = 0;
blockhdr->next = NULL;
return (HANDLE)mem;
} // CreateMyHeap
|
This actually adds pages to the address space
by calling ::VirtualAlloc to obtain the pages. The pages become
real because I specify MEM_COMMIT, and they are normal data pages
(read/write) because I specify the access as PAGE_READWRITE. If the allocation succeeds, I initialize the heap. The heap has a SegmentHeader at the front, and the rest of the space is represented by a single, large block of free storage, defined by a BlockHeader. Note the trick of converting the address of the "next" segment header to be interpreted as a block header. The block has a size of "everything that is left", so we subtract off the size of the segment header and the size of the block header. The block is now marked as a "free" block, and since it is the one-and-only free block, there is no "next block" for the next pointer to reference. The segment header is going to have a CRITICAL_SECTION that allows us to safely call these methods concurrently from multiple threads, and that CRITICAL_SECTION must be initialized here. Finally, we cast the pointer to a HANDLE and return it. Note that a HANDLE is always a pointer-sized object, meaning it is 32 bits in Win32 and 64 bits in Win64. |
||||||||||||||||||||||||||||||||||||||||||||||||
/**************************************************************************** * DestroyMyHeap * Inputs: * HANDLE heap: Heap handle * Result: void * * Effect: * Destroys the heap ****************************************************************************/ |
This function destroys the
heap that was created by CreateMyHeap. Note that this does not take into account the fact that the application may still have blocks allocated within the space that is about to be released. A robust implementation might check to make sure that there are no residual blocks left. This simple implementation does not support this kind of "debug support". |
||||||||||||||||||||||||||||||||||||||||||||||||
void DestroyMyHeap(HANDLE heap)
{
if(heap == NULL)
return;
SegmentHeader * seghdr = (SegmentHeader *)heap;
DeleteCriticalSection(&seghdr->lock);
::VirtualFree(heap, seghdr->size, MEM_RELEASE);
} // DestroyMyHeap
|
This illustrates how a HANDLE type is
converted back into a pointer. This idiom is common when the HANDLE
type or one of its equivalents is used to represent an opaque data type. Note that the CRITICAL_SECTION must be deallocated before the storage is released. The ::VirtualFree API returns the storage to the operating system. The address range represented is removed from the application's address space. |
||||||||||||||||||||||||||||||||||||||||||||||||
/**************************************************************************** * AllocMyHeap * Inputs: * HANDLE heap: Heap header pointer * SIZE_T size to allocate * Result: LPVOID * Pointer to the allocated storage, or NULL * Effect: * Allocates a block of memory. *****************************************************************************/ |
This is an illustrative
example to familiarize the person studying it with the concept of how
allocators work. Real allocators are vastly more sophisticated, but all they
do is what this one does, only faster, with lower fragmentation. For example, this code implements "first fit", which minimizes performance and maximizes memory fragmentation. It is the role of real allocators to avoid both of these issues Real allocators will also have a lot of integrity checks on the the values in the header to protect against memory damage, attempts to free storage twice, and similar blunders. These have been omitted to concentrate on the "core" logic of the allocation |
||||||||||||||||||||||||||||||||||||||||||||||||
LPVOID AllocMyHeap(HANDLE heap, SIZE_T size)
{
if(size == 0)
return NULL; // zero allocation returns NULL
if(heap == NULL)
return NULL;
|
This shows two simple tests that will catch some classical user errors and not cause a crash in the allocator due to an access fault or cause some other malfunction. | ||||||||||||||||||||||||||||||||||||||||||||||||
SIZE_T AllocSize = ALLOCSIZE(size); |
This rounds the request up to the next allocation quantum. | ||||||||||||||||||||||||||||||||||||||||||||||||
SegmentHeader * seghdr = (SegmentHeader *)heap;
BlockHeader * blockhdr = (BlockHeader *)&seghdr[1];
LPVOID result = NULL;
|
These lines compute the addresses of the heap
segment header (so we can set the heap segment lock) and the address of the
first block in the storage chain. The result is assumed to be NULL unless modified by the loop. It will be modified only if a satisfactory block is found. |
||||||||||||||||||||||||||||||||||||||||||||||||
EnterCriticalSection(&seghdr->lock); |
This sets a lock that prevents any other thread from attempting to manipulate the heap, until this code has finished its task. Note that there must be no return statements in the body of the code | ||||||||||||||||||||||||||||||||||||||||||||||||
while(TRUE)
{ /* scan for first fit */
|
At this point, we are going to walk through the
linked list of objects, one at a time, looking for a free block of storage
that is large enough to satisfy the input request.. If we come to the end of the list, as indicated by blockhdr being NULL, we are done with the loop. If we find a block that is allocated, we ignore it and move to the next block. |
||||||||||||||||||||||||||||||||||||||||||||||||
if(blockhdr->size >= AllocSize)
{ /* it's big enough */
|
There are two conditions of interest here: either the free block is "big enough" or it is not. We ignore any block which is not "big enough". | ||||||||||||||||||||||||||||||||||||||||||||||||
// Split or not?
|
If we split a block, it leaves us with a second
block. If this second block is not big enough to hold something
useful, then splitting it only fragments memory and creates small but
unusable blocks that may not be reusable, ever.
This code checks to see if it is necessary to split the block, or worth splitting the block. |
||||||||||||||||||||||||||||||||||||||||||||||||
// if delta is 0, we have an exact fit
if(delta == 0)
{ /* perfect match */
result = (LPVOID)&blockhdr[1];
blockhdr->allocated = size;
break;
} /* perfect match */
|
If the block is a perfect match, we are done. We mark the allocated field with the actual size of the allocation and return the pointer to the block. Note that the block remains in the list, so there is no need to adjust the next pointer. | ||||||||||||||||||||||||||||||||||||||||||||||||
// if delta is too small to hold a header + SPLIT_LIMIT
// bytes of useful space, do not split
|
Split the block. This is done by putting a new block header in, and linking the next pointer of the current blkhdr to it, while it links to the block that blkhdr used to point to. The figure to the left shows what we are starting with. If the value of delta - sizeof(BlockHeader) is too small, that is, if it is lower than the SPLIT_LIMIT, then we do not split the block but just allocate the extra space to the current block. This keeps us from developing useless small blocks that cannot be allocated for any purpose. Note that SPLIT_LIMIT here is a compile-time constant, but it could be computed on-the-fly to make the allocator adaptive; that's beyond the scope of this simple allocator. |
||||||||||||||||||||||||||||||||||||||||||||||||
BlockHeader * newhdr = (BlockHeader *)
(((BYTE *)blockhdr) + AllocSize + sizeof(BlockHeader));
newhdr->size = delta - sizeof(BlockHeader);
newhdr->allocated = 0; // no space is allocated in this new block
newhdr->next = blockhdr->next;
blockhdr->next = newhdr;
blockhdr->size = AllocSize;
blockhdr->allocated = size;
result = (LPVOID)&blockhdr[1];
// This is the structure we now have
|
It is big enough to justify splitting it. Create a pointer to the place where the new block header (newhdr) should be. Link up the blocks appropriately. We have found a block, and we will return it. | ||||||||||||||||||||||||||||||||||||||||||||||||
else
{ /* it's too small */
// Skip this block if it is too small
blockhdr = (BlockHeader *)blockhdr->next;
} /* it's too small */
} /* scan for first fit */
|
The block was too small, even though it was free. Skip to the next block. | ||||||||||||||||||||||||||||||||||||||||||||||||
LeaveCriticalSection(&seghdr->lock);
return result;
} // AllocMyHeap
|
Release the CRITICAL_SECTION.
Return the result. Note that in some cases, result has been initialized to NULL but no block was found, so the value NULL is returned. |
||||||||||||||||||||||||||||||||||||||||||||||||
/**************************************************************************** * FreeMyHeap * Inputs: * HANDLE heap: Heap handle * LPVOID mem: Memory address * Result: void * * Effect: * Frees the storage ****************************************************************************/ |
This frees a block of storage that has been allocated from the heap. | ||||||||||||||||||||||||||||||||||||||||||||||||
void FreeMyHeap(HANDLE heap, LPVOID mem)
{
if(heap == NULL)
return;
if(mem == NULL)
return;
SegmentHeader * seghdr = (SegmentHeader *)heap;
EnterCriticalSection(&seghdr->lock);
BlockHeader * blockhdr = (BlockHeader *) ((LPBYTE)mem - sizeof(BlockHeader));
blockhdr->allocated = 0;
LeaveCriticalSection(&seghdr->lock);
} // FreeMyHeap
|
After performing a couple simple sanity tests
that avoid taking access faults, the SegmentHeader is located, and
the heap lock is set. The BlockHeader address is computed, and used to modify the block header. To free the storage, the allocated length is set to 0. Note that there is no coalescing going on here. The block remains as a block of its specified size and is not combined with adjacent blocks ("aggressive coalescing"). The CRITICAL_SECTION is unlocked and the free operation is finished. |
||||||||||||||||||||||||||||||||||||||||||||||||
/**************************************************************************** * CoalesceMyHeap * Inputs: * HANDLE heap: Heap handle * Result: void * * Effect: * Coalesces adjacent free blocks ****************************************************************************/ |
This will coalesce adjacent
free blocks into a single free block. This is a simplistic method that assumes the blocks are linked in ascending address order. If you were to change this (as suggested in one of the possible "Improvements"), then a different strategy will be required to determine block adjacency. Note that aggressive coalescing works at odds to certain other optimizations, such as "Quick Fit" and "Best Fit". |
||||||||||||||||||||||||||||||||||||||||||||||||
void CoalesceMyHeap(HANDLE heap)
{
if(heap == NULL)
return;
SegmentHeader * seghdr = (SegmentHeader *)heap;
EnterCriticalSection(&seghdr->lock);
|
After the usual simple test to make sure we don't crash with an access fault | ||||||||||||||||||||||||||||||||||||||||||||||||
BlockHeader * blockhdr = (BlockHeader *)&seghdr[1];
while(TRUE)
{ /* scan heap */
if(blockhdr == NULL)
break;
if(blockhdr->next == NULL)
break;
|
Scan the heap from front to back (noting that in this heap we are always keeping the blocks in address order, so next always refers to the block not only logically next but physically next in the sequence). If the current blockhdr is NULL, we are done, and if the next is NULL, we have no next block to merge with. So either of these tests will terminate the loop. | ||||||||||||||||||||||||||||||||||||||||||||||||
BlockHeader * nexthdr = (BlockHeader *)blockhdr->next; |
Get a pointer to the next header | ||||||||||||||||||||||||||||||||||||||||||||||||
if(blockhdr->allocated != 0)
{ /* allocatd, skip it */
blockhdr = (BlockHeader *)nexthdr->next;
continue;
} /* allocated, skip it */
|
If the block is allocated, we do not consider it for coalescing. We skip over it and start looking again at the block that follows it (note this could be NULL) | ||||||||||||||||||||||||||||||||||||||||||||||||
// It is a free header. Coalesce it with the next block
// if the next block is free
if(((BlockHeader *)(blockhdr->next))->allocated != 0)
{ /* next allocated, skip it */
blockhdr = (BlockHeader *)((BlockHeader *)(blockhdr->next))->next;
continue;
} /* next allocated, skip it */
|
It is a free block.
If the next block is not free, there is no possibility of coalescing, so we skip to the block that follows the next block. |
||||||||||||||||||||||||||||||||||||||||||||||||
// Coalesce the two
blockhdr->size = blockhdr->size +
((BlockHeader *)blockhdr->next)->size + sizeof(BlockHeader);
blockhdr->next = ((BlockHeader *)blockhdr->next)->next;
} /* scan heap */
|
Coalesce the two blocks. Note the size is not just the sum of the two sizes, but also the space occupied by the BlockHeader of the second block. | ||||||||||||||||||||||||||||||||||||||||||||||||
LeaveCriticalSection(&seghdr->lock);
} // CoalesceMyHeap
|
Unlock the heap segment and return. | ||||||||||||||||||||||||||||||||||||||||||||||||
There are lots of ways to improve this allocator. Here are just a few ideas:
Most of the behavior should be self-explanatory. However, there is one feature which may not be obvious: the scripting engine. As I was developing experiments, I found that I got tired of trying to remember the sequence of operations I used to produce a particular picture. So I added a little scripting language to the program. It allows the following commands. Note that using the scripting language it is possible to get block sizes for alloc or alloc1k that are different from the powers-of-2 buttons or from the allocate-1024-1-byte-blocks button.
There are menu items to load a script file, save a script file, edit a script file, clear the script file, and play the current script file. The Record button allows you to capture your current actions to the script file. The Size button records the window's current size so it can be reset to that size upon playback. Sometimes, after you have run an experiment, you may want to change the window size to make it look good. Hit the Size button to record the size.
| Command/parameters | Action | Created by |
create size |
Creates a heap of the specified size. | CreateMyHeap |
alloc size |
Allocates a block of size bytes | 1K, 2K, 4K, 8K, 16K, 32K, 64K |
alloc1k size |
Performs 1024 allocations of a block of the specified size | 1K*1 |
free index |
Frees the block whose index is specified | Free |
coalesce |
Causes a coalesce operation | CoalesceMyHeap |
size width, height |
Sets the window size to be width, height | Size |
capture "filename" |
Captures the image of the window to the bitmap file whose name is given | Capture |
destroy |
Destroys the heap | FreeMyHeap |
# anything |
A comment | Hand-editing the script file |
 VS 2008
source code.
VS 2008
source code.
![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.
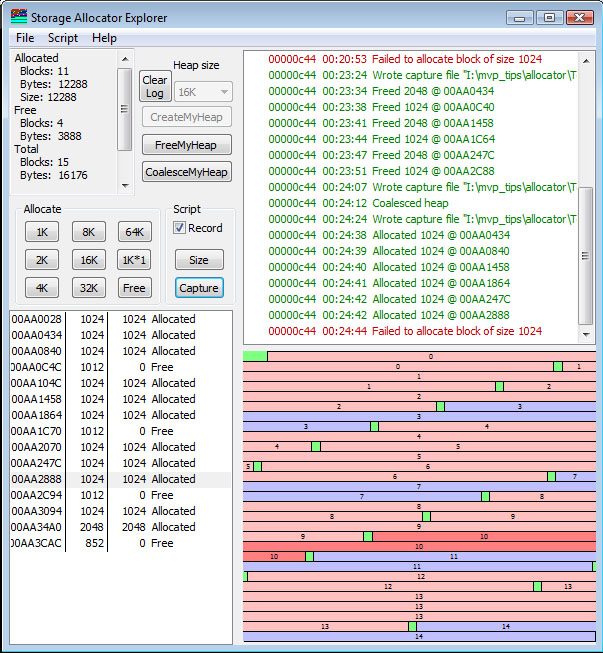 Allocated
Blocks: 11
Bytes: 12288
Size: 12288
Free
Blocks: 4
Bytes: 3888
Total
Blocks: 15
Bytes: 16176
Size: 16176
Overhead 208
Padding 0
Allocated
Blocks: 11
Bytes: 12288
Size: 12288
Free
Blocks: 4
Bytes: 3888
Total
Blocks: 15
Bytes: 16176
Size: 16176
Overhead 208
Padding 0 if(blockhdr == NULL)
break;
if(blockhdr->allocated != 0)
{ /* skip it */
blockhdr = (BlockHeader *)blockhdr->next;
continue;
} /* skip it */
if(blockhdr == NULL)
break;
if(blockhdr->allocated != 0)
{ /* skip it */
blockhdr = (BlockHeader *)blockhdr->next;
continue;
} /* skip it */ 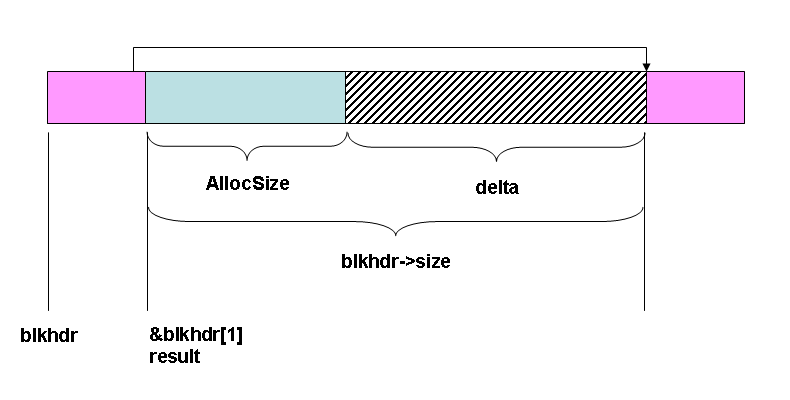 SIZE_T delta = blockhdr->size - AllocSize;
//
SIZE_T delta = blockhdr->size - AllocSize;
//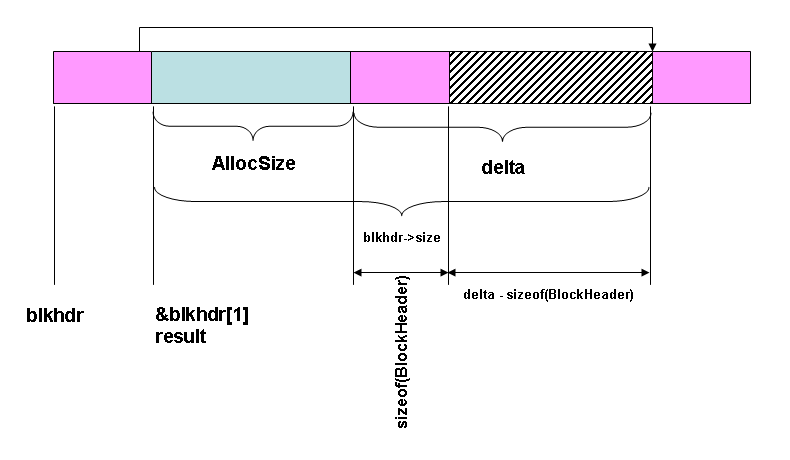 if(delta < sizeof(BlockHeader) + SPLIT_LIMIT)
{ /* no split */
result = (LPVOID)&blockhdr[1];
blockhdr->allocated = size;
break;
} /* no split */
if(delta < sizeof(BlockHeader) + SPLIT_LIMIT)
{ /* no split */
result = (LPVOID)&blockhdr[1];
blockhdr->allocated = size;
break;
} /* no split */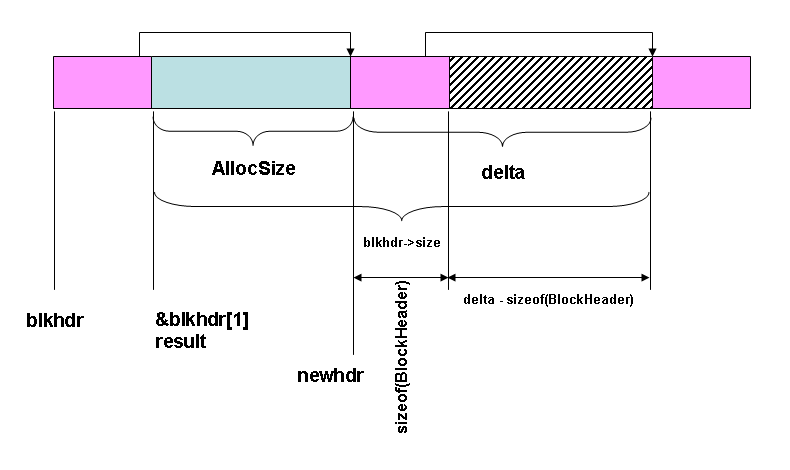 break;
} /* it's big enough */
break;
} /* it's big enough */